Python NLTK学习8(正则表达式分块器)
本系列博客为学习《用Python进行自然语言处理》一书的学习笔记。
引言
一个句子在分成一个个词后,我们还可以将一个或多个连续的词分成一块。分成的块通常代表一个整体,例如在句子"We saw the yellow dog"中,"the yellow dog"可以看作是一个块,像这样的块我们一般称为名词短语块。分块是用于实体识别的基本技术。
名词短语分块
名词短语分块也叫做NP-分块,NP-分块信息最有用的来源之一是词性标记,所以我们一般在分块前都会进行词性标注。
正则表达式分块器
为了创建一个NP-块,我们需要定义NP-块的块语法。正则表达式分块器接受正则表达式规则定义的语法来对文本进行分块,我们先看一个例子:
import nltk
# 分词
text = "the little yellow dog barked at the cat"
sentence = nltk.word_tokenize(text)
# 词性标注
sentence_tag = nltk.pos_tag(sentence)
print(sentence_tag)
# 定义分块语法
# 这个规则是说一个NP块由一个可选的限定词后面跟着任何数目的形容词然后是一个名词组成
# NP(名词短语块) DT(限定词) JJ(形容词) NN(名词)
grammar = "NP: {<DT>?<JJ>*<NN>}"
# 进行分块
cp = nltk.RegexpParser(grammar)
tree = cp.parse(sentence_tag)
tree.draw()
示例中我们先进行分词,词性标注,之后我们定义了一个分块语法"NP: {...}",该语法中的NP就是代表我们的块名称,一对{}就是把大括号中语法匹配到的词做为一块,使用该语法构造出一个正则表达式分块器就可以对标注词性的文本进行分块,分块结果是一个Tree对象。
该示例的结果为:
[('the', 'DT'), ('little', 'JJ'), ('yellow', 'JJ'), ('dog', 'NN'), ('barked', 'VBD'), ('at', 'IN'), ('the', 'DT'), ('cat', 'NN')]
从分块结果中我们可以看到"the little yellow dog"和"the cat"都被正确的分块为NP-块。
多条规则的正则表达式分块器
上面的例子只有一条语法规则,如果面对复杂的情况就不太适用,我们可以定义多条分块规则。面对多条规则,分块器会轮流应用分块规则,依次更新块结构,所有的规则都被调用后才返回。我们先看一个示例:
import nltk
# 分词
text = "Lucy let down her long golden hair"
sentence = nltk.word_tokenize(text)
# 词性标注
sentence_tag = nltk.pos_tag(sentence)
print(sentence_tag)
# 定义分块语法
# NNP(专有名词) PRP$(格代名词)
# 第一条规则匹配可选的词(限定词或格代名词),零个或多个形容词,然后跟一个名词
# 第二条规则匹配一个或多个专有名词
# $符号是正则表达式中的一个特殊字符,必须使用转义符号\来匹配PP$
grammar = r"""
NP: {<DT|PRP\$>?<JJ>*<NN>}
{<NNP>+}
"""
# 进行分块
cp = nltk.RegexpParser(grammar)
tree = cp.parse(sentence_tag)
tree.draw()
该示例的结果为:
[('Lucy', 'NNP'), ('let', 'VBD'), ('down', 'RP'), ('her', 'PRP$'), ('long', 'JJ'), ('golden', 'JJ'), ('hair', 'NN')]

从分块结果可以看到"Lucy"和"her long golden hair"都符合我们的分块预期。
加缝隙
上面两个例子我们都是根据定义的块规则来找到块,反过来想,我们可以定义非块结构的规则,然后把找到的非块给排除掉。以上的过程叫做加缝隙,加缝隙是从一大块中去除一个标识符序列的过程。如果匹配的标识符序列出现在块的中间,这些标识符会被去除,在以前只有一个块的地方留下两个块。如果序列在块的周边,这些标记被去除,留下一个较小的块。我们先看一个例子:
import nltk
# 分词
text = "the little yellow dog barked at the cat"
sentence = nltk.word_tokenize(text)
# 词性标注
sentence_tag = nltk.pos_tag(sentence)
print(sentence_tag)
# 定义缝隙语法
# 第一个规则匹配整个句子
# 第二个规则匹配一个或多个动词或介词
# 一对}{就代表把其中语法匹配到的词作为缝隙
grammar = r"""
NP: {<.*>+}
}<VBD|IN>+{
"""
cp = nltk.RegexpParser(grammar)
# 分块
tree = cp.parse(sentence_tag)
tree.draw()
该示例的结果为:
[('the', 'DT'), ('little', 'JJ'), ('yellow', 'JJ'), ('dog', 'NN'), ('barked', 'VBD'), ('at', 'IN'), ('the', 'DT'), ('cat', 'NN')]
该示例的结果结果和第一个例子的结果一致。
NLTK Tree
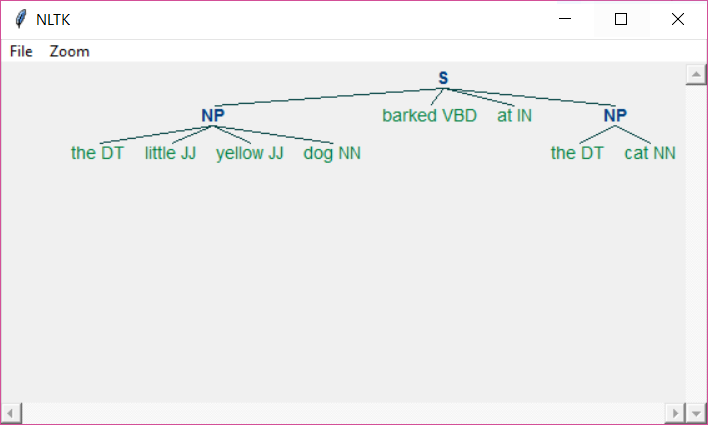
树继承自列表,树的孩子是以列表的方式进行存储的。树的孩子可以是一个叶子结点或者子树结点,叶子结点没有孩子,子树结点有孩子,子树也是树。树有一个标签属性,可以使用.label()方法进行查看。如下图就是[('the', 'DT'), ('little', 'JJ'), ('yellow', 'JJ'), ('dog', 'NN'), ('barked', 'VBD'), ('at', 'IN'), ('the', 'DT'), ('cat', 'NN')]分块后的树结构:
 树根的标签为'S',它有4个孩子,4个孩子以列表的方式存储。树根的孩子0和孩子3是子树,它们的标签是'NP'。树根的孩子1和孩子2是叶子,它们是元组对象。
树根的标签为'S',它有4个孩子,4个孩子以列表的方式存储。树根的孩子0和孩子3是子树,它们的标签是'NP'。树根的孩子1和孩子2是叶子,它们是元组对象。
总结
- RegexpParser(grammar):构造函数,接受分块语法,返回一个正则表达式分块器
- RegexpParser::parse(tokens):针对标注词性的列表进行分块,返回一个Tree对象
- Tree::draw():绘制树形结构
- Tree::label():返回树的标签
- Tree::subtrees():返回所有的子树,包括子树的子树
- Tree::leaves():返回所有的叶子,包括子树的叶子
NLTK词性标注符号含义
CC 连接词
CD 基数词
DT 限定词
EX 存在
FW 外来词
IN 介词或从属连词
JJ 形容词或序数词
JJR 形容词比较级
JJS 形容词最高级
LS 列表标示
MD 情态助动词
NN 常用名词 单数形式
NNS 常用名词 复数形式
NNP 专有名词 单数形式
NNPS 专有名词 复数形式
PDT 前位限定词
POS 所有格结束词
PRP 人称代词
PRP$ 所有格代名词
RB 副词
RBR 副词比较级
RBS 副词最高级
RP 小品词
SYM 符号
TO to 作为介词或不定式格式
UH 感叹词
VB 动词基本形式
VBD 动词过去式
VBG 动名词和现在分词
VBN 过去分词
VBP 动词非第三人称单数
VBZ 动词第三人称单数
WDT 限定词
WP 代词
WP$ 所有格代词
WRB 疑问代词
其他章节链接
Python NLTK学习8(正则表达式分块器)





还没有人评论...