Python NLTK学习1(Text对象)

本系列博客为学习《用Python进行自然语言处理》一书的学习笔记。
搭建环境
- Python版本为3.5
- IDE:PyCharm
- PyCharm中安装NLTK和matplotlib
Python版本可以随意选择,只要NLTK支持就可以。IDE的话笔者习惯使用Pycharm在Windows下进行Python开发,而且PyCharm中安装Python库也很方便,随自己喜好。
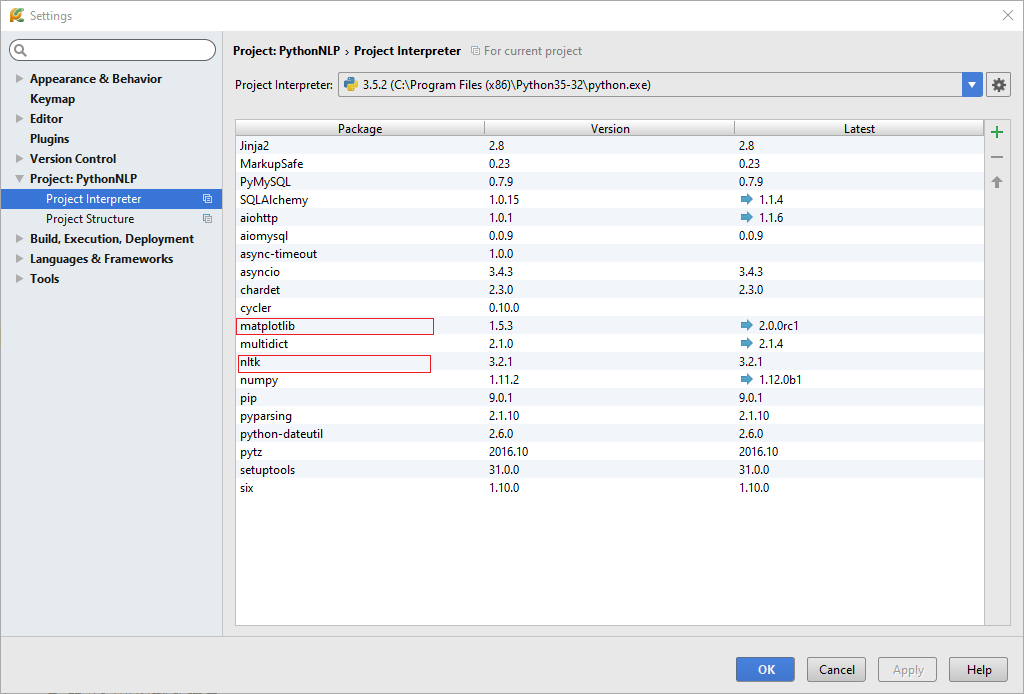
打开Python3.5解释器,输入如下代码:
import nltk
nltk.download()
如果出现错误,则说明你的NLTK没有安装成功,没问题的话我们就可以看到如下对话框:

设置好下载目录,选择book选项,点击下载。《用Python进行自然语言处理》这本书中所用到的所有书籍数据都在book选项下,下载时间可能有点长,需要耐心等待。下载完成后我们的基本环境就搭建完成啦。
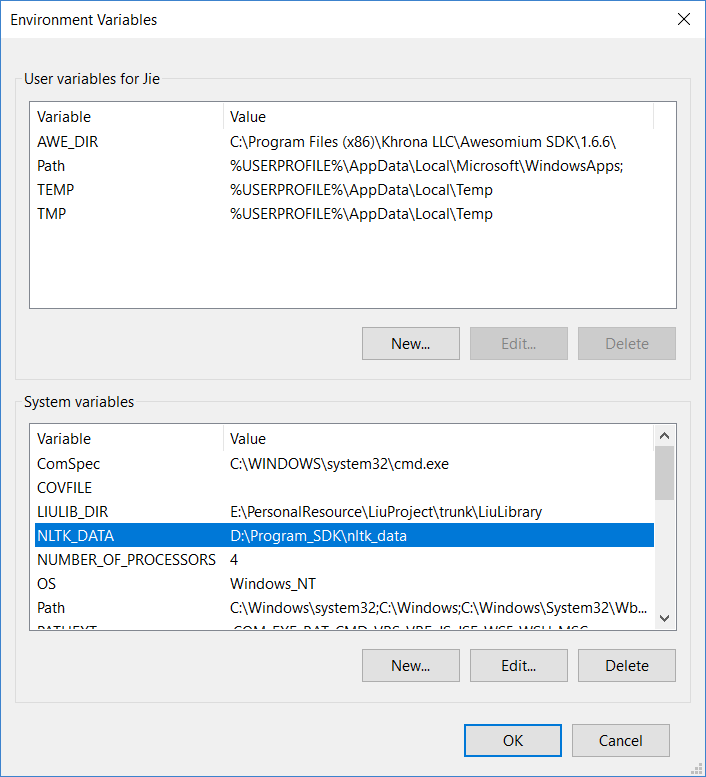
Windows下设置下载目录后需要在系统环境变量中设置一个NTLK_DATA变量,重启电脑后生效,如下:
输入下面代码来看看书籍数据:
import nltk
form nltk.book import *
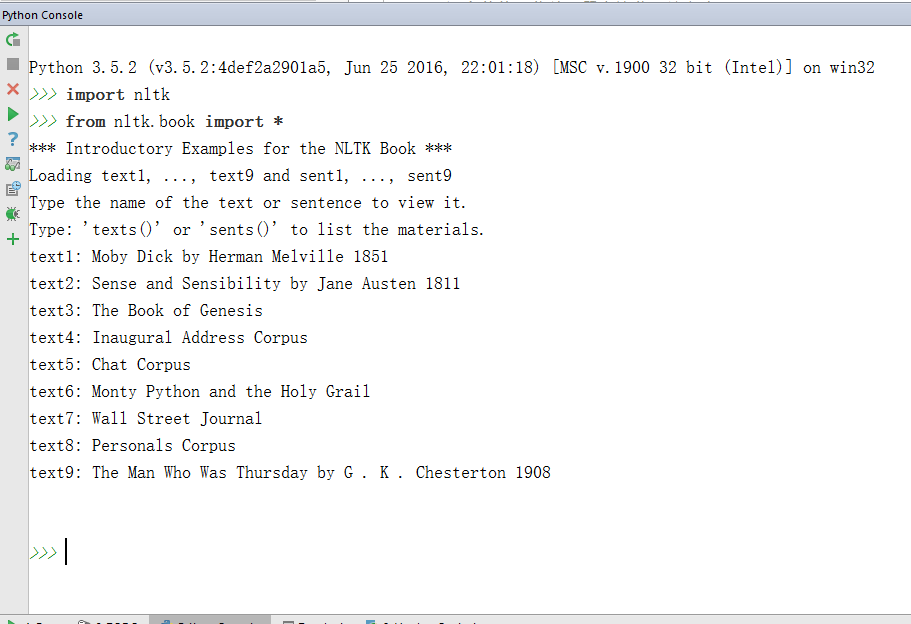
我们可以看到nltk预先帮我们加载了一些书籍数据text1~text9,text1~text9为Text类的实例对象名称,它们都代表一本书籍。实际上Text类的构造函数接受一个单词列表作为参数,NLTK库预先帮我们构造了几个Text对象。
搜索文本
Text::concordance(word):该方法接受一个单词字符串,会打印出输入单词在文本中出现的上下文,查看单词的上下文可以帮助我们了解单词的词性。
text1.concordance('monstrous')
结果如下:
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ... This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himmal
they might scout at Moby Dick as a monstrous fable , or still worse and more de
th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
从输出结果我们可以看到monstrous这个单词的上下文,如a _ size,the _ Pictures等。
Text::similar(word):该方法接受一个单词字符串,会打印出和输入单词具有相同上下文的其他单词,也就是说找出和指定单词相似的其他单词,比如monstrous用在the_Pictures上下文中,similar方法会打印出所有使用the_Pictures上下文的单词。
text1.similar('monstrous')
结果如下:
gamesome lazy wise untoward horrible mystifying uncommon mean fearless contemptible few domineering vexatious imperial careful impalpable puzzled mouldy determined abundant
使用方法text1.concordance('gamesome'),我们可以看到gamesome和monstrous具有相同的上下文most_and。
Text::common_contexts(words):该方法接受一个单词列表,会打印出列表中所有单词共同的上下文。
text1.common_contexts(['monstrous', 'gamesome'])
结果为:
most_and
这和我们使用concordance方法,自己观察的结果一致。
Text::dispersion_plot(words):该方法接受一个单词列表,会绘制每个单词在文本中的分布情况。
text4.dispersion_plot(['freedom', 'America'])
结果为:
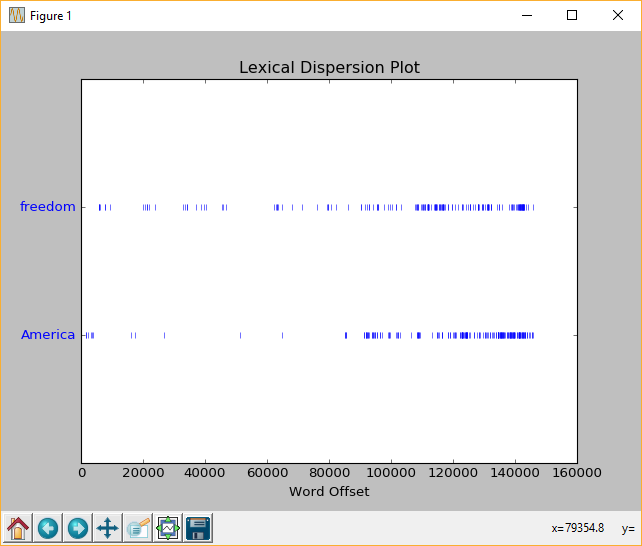
我们可以看到freedom和America基本都集中在文本的后半段。
计数词汇
定位到NLTK的text.py文件中,我们可以看到Text中实现了如下代码:
def __getitem__(self, i):
if isinstance(i, slice):
return self.tokens[i.start:i.stop]
else:
return self.tokens[i]
def __len__(self):
return len(self.tokens)
说明Text对象支持len()以及索引和切片,我们可以把Text对象看做是一个单词列表。
获取文本单词总数目:
len(text1)
获取不重复单词数目:
len(set(text1))
Text::count(word):该方法接受一个单词,返回该单词在文本中出现的次数。
text1.count('monstrous')
结果为:
10
词语搭配和双连词
Text::collocations():该方法会打印出文本中频繁出现的双连词。
text1.collocations()
结果为:
Sperm Whale; Moby Dick; White Whale; old man; Captain Ahab; sperm whale; Right Whale; Captain Peleg; New Bedford; Cape Horn; cried Ahab; years ago; lower jaw; never mind; Father Mapple; cried Stubb; chief
总结
Text成员方法:
- __init__(words),构造函数接受单词列表作为参数
- collocations(),打印出频繁出现的双连词
- concordance(word),打印指定单词在文本中的所有上下文
- similar(word),打印和指定单词具有相同上下文的所有单词
- common_contexts(words),打印出列表中所有单词的共同上下文
- dispersion_plot(words),绘制列表中所有单词在文本中的分布情况
- count(word),返回指定单词在文本中出现的次数
Text对象支持操作:
- len()函数
- 索引和切片
其他章节链接
Python NLTK学习1(Text对象)





还没有人评论...